Yapay zeka gelişiyor ama akıl yürütme (yani problemi adım adım çözme) hala en sert engellerden biriydi. DeepSeek AI ekibi, R1 ailesinde bu eşiği yeni bir eğitim stratejisiyle aştı. Geleneksel yöntemin aksine modele insan çözümlerini kopyalatmak yerine, doğru sonuca ulaştığında ‘ödüllendirilen’ bir süreç kuruldu; böylece model, insan rehberliğine bağımlı olmadan kendi çözüm stratejilerini geliştirdi.
TAKVİYELİ ÖĞRENME ATAĞI
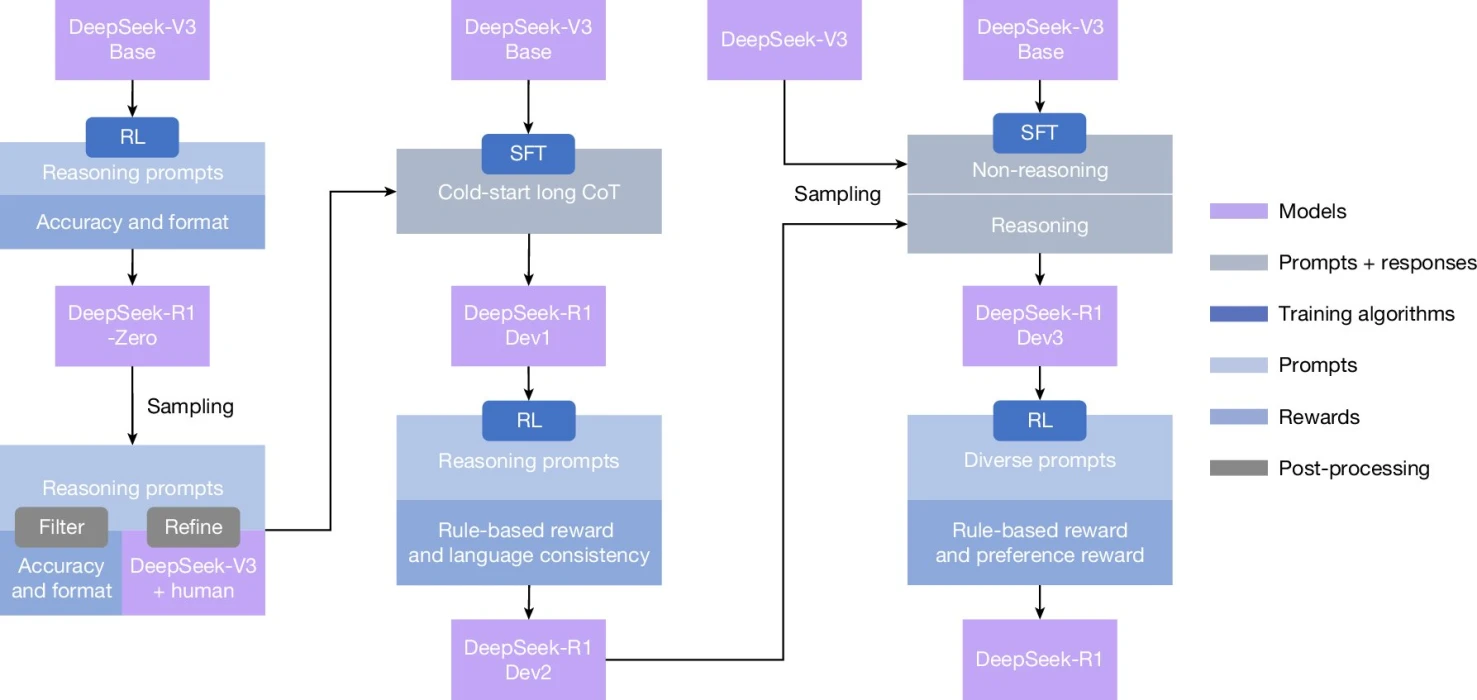
Ekip, takviyeli öğrenme (reinforcement learning) çerçevesinde R1’i zorlu matematik, kodlama ve fen problemleriyle karşılaştırdı. Eğitimde tek geri bildirim, nihai cevabın doğru olup olmadığına dair bir sinyaldi. Bu sayede model; çalışmasını denetleme, alternatif yol arama, ‘bekle’ benzeri kontrol işaretleri üretme gibi üst-düzey beceriler sergiledi. Etkin stratejiler pekiştirilirken, yanlış açılımlar kendi kendine elendi. Sürecin geç safhalarında, sınırlı insan müdahalesi yalnızca ince ayar için devreye girdi.
SONUÇLAR ÇARPICI OLDU
R1, insan örnekleriyle eğitilmiş muadillerine kıyasla çeşitli kıyas testlerinde üstün geldi. En çarpıcı gösterge, seçkin lise öğrencilerinin katıldığı AIME 2024 sınavında yüzde 86,7 doğruluk oldu. Bu performans, modelin adım adım akıl yürütme kapasitesinin gerçek dünya benzeri zorluklarda da çalıştığını ortaya koyuyor.
HATALAR VE SINIRLAR
Araştırmacılar, mevcut kısıtları da not düşüyor: İngilizce dışı istemlerde dil karışmaları, kimi basit problemleri gereğinden fazla karmaşıklaştırma eğilimi görüldü. Bu hatalar azaltıldığında, otonom akıl yürütme yeteneğinin daha kabiliyetli ve daha az insan güdümlü modellerin önünü açacağı öngörülüyor.
YENİ DÖNEM KAPIDA
Modeli her adımda ‘öğretmek’ yerine sonuca göre ödüllendirmek, insan önyargılarının taşınmasını da sınırlayabiliyor. DeepSeek’in bulguları, akıl yürütme becerisinin geniş ölçekli, insan-etiketli veri bağımlılığından kurtulabileceğine işaret ediyor. Bu yaklaşımın, bilimsel hesaplamadan yazılım geliştirmeye pek çok alanda daha güvenilir, genellenebilir yapay zeka sistemlerine kapı aralaması bekleniyor.